Financial Institutions Survey Analysis
1. Data
Survey data consist of the 99 observations and 73 variables.
This study focuses on assessing the internal control systems and their impact on the operational
efficiency of financial institutions in Nigeria.
2. Clean data, convert data

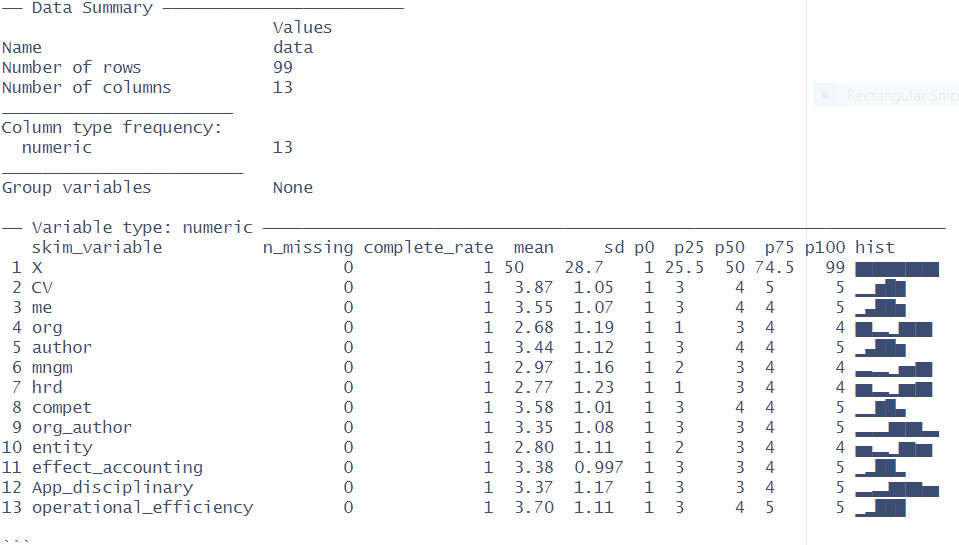
3. Data summary
4. Plot distribution

5.Multi linear regression model statistics
Use the multi linear model statistics
In this case will use operational efficiency as dependent variable, and the independent
variables, as example:
Variables need to be abbreviated to make it easier to create a model.
CV: "section_a_control_environment_the_following_statements_pertain_to_how_the_control_environment_influences_the_financial_performance_of_the_microfinance_bank_please_rate_each_statement_according_to_your_understanding_by_selecting_the_appropriate_option_communication_and_enforcement_of_integrity_and_ethical_values_within_our_microfinance_bank_are_adequate",
me: "our_microfinance_bank_management_is_dedicated_to_ensuring_employee_competence_in_financial_matters", org: "the_managements_philosophy_and_operating_style_promote_the_microfinance_banks_growth_while_maintaining_adherence_to_rules_and_regulations", author: "the_microfinance_bank_s_organizational_structure_has_clear_lines_for_reporting_and_decision_making_hierarchies", mngm: "our_microfinance_banks_management_appropriately_assigns_authority_and_responsibility_to_qualified_individuals", hrd: "we_have_well_designed_human_resource_policies_that_are_easy_to_implement_and_practice_within_our_microfinance_bank", compet: "the_microfinance_bank_is_committed_to_ensuring_competence_in_job_specific_requirements_and_the_translation_of_ those_requirements_into_necessary_knowledge_and_skills", org_author: "the_organization_assigns_authority_and_responsibility_to_foster_accountability_and_control", entity: "the_entity_assigns_authority_and_responsibility_to_provide_a_basis_for_accountability_and_control", effect_accounting: "the_microfinance_bank_has_an_effective_accounting_and_financial_management_system_in_place", App_disciplinary: "appropriate_disciplinary_actions_are_taken_when_employees_fail_to_comply_with_policies_procedures_or_behavioral_standards",
#---Dependent variable
operational efficiency: "section_f_operational_efficiency_please_indicate_your_level_of_agreement_with_the_following_statements_regarding_the_performance_of_your_organization_microfinance_bank_s_financial_statements_aim_to_provide_a_comprehensive_overview_of_the_organization_s_performance_and_position_at_a_specific_point_in_time"
6.1 Control environment
To assess the effect of the control environment on the operational efficiency of financial institutions.
We can see from the table of the multi linier statistics model regression:
#---
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 2.7653917 0.7311077 3.782 0.000286 ***
# X -0.0011205 0.0040307 -0.278 0.781693
# CV 0.0008834 0.1259978 0.007 0.994422
# me -0.0411602 0.1206962 -0.341 0.733918
# org -0.1852678 0.1055421 -1.755 0.082753 .
# author -0.1898709 0.1128253 -1.683 0.096027 .
# mngm 0.0548492 0.1015565 0.540 0.590534
# hrd 0.2139908 0.0952287 2.247 0.027192 *
# compet 0.2940369 0.1283810 2.290 0.024448 *
# org_author -0.0739613 0.1143838 -0.647 0.519609
# entity -0.0863652 0.1106345 -0.781 0.437160
# effect_accounting 0.2746892 0.1316306 2.087 0.039865 *
# App_disciplinary 0.0099777 0.1087175 0.092 0.927089
#---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# Residual standard error: 1.079 on 86 degrees of freedom
# Multiple R-squared: 0.1715, Adjusted R-squared: 0.05595
# F-statistic: 1.484 on 12 and 86 DF, p-value: 0.1459
The three variables hrd(0.027192 *),compet( 0.024448 *) and effect_accounting(0.039865 *) have weak effects on the operational efficiency of financial institutions.
The CV variable(0.994422) have no statistical influence to operational efficiency of financial.
Based on the F-statistic of the model 1.484 and the corresponding p-value: 0.1459. This indicates that the overall model is not statistically significant because the p-value: 0.1459 is greater than 0.05.
6.2. Risk assessment
#----
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 2.334e+00 5.144e-01 4.536 1.69e-05 ***
# 6.325e-05 3.532e-03 0.018 0.9857
# risk_assessment 2.588e-01 1.025e-01 2.524 0.0133 *
# financial_management 1.458e-01 9.261e-02 1.574 0.1188
# staff 2.319e-02 7.997e-02 0.290 0.7725
#---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# Residual standard error: 0.9959 on 94 degrees of freedom
# Multiple R-squared: 0.131, Adjusted R-squared: 0.09401
# F-statistic: 3.542 on 4 and 94 DF, p-value: 0.009747
#---
Variable "risk_assessment"(0.0133 *) affect the operational_efficiency of financial institutions.
Based on the F-statistic of the model 3.542 and the corresponding p-value: 0.009747. This indicates that the model is statistically significant because the p-value: 0.009747 is less than 0.05
6.4. Information and communication
Information and communication systems have a significant positive effect on the operational efficiency of financial institutions.
#---
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#( Intercept) 1.8123028 0.4972051 3.645 0.000438 ***
# X -0.0005646 0.0033737 -0.167 0.867456
# information_and_communication 0.2293080 0.0962420 2.383 0.019203 *
# communicated_in_an_accurate_clear 0.2965128 0.0953769 3.109 0.002485 **
# relevant_information 0.0661351 0.0857489 0.771 0.442484
#---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# Residual standard error: 0.9504 on 94 degrees of freedom
# Multiple R-squared: 0.2087, Adjusted R-squared: 0.175
# F-statistic: 6.197 on 4 and 94 DF, p-value: 0.0001804
#---
From the above table we can see that:
The communicated_in_an_accurate_clear (0.002485 **) has the stronger influence to the operational efficiency than the variable information_and_communication(0.019203 *).
Based on the F-statistic of the model 6.197 and the corresponding p-value: 0.0001804. This indicates that overall the model is statistically significant because the p-value: 0.0001804 is much smaller than 0.05
6.5. Monitoring
To investigate the result of information and communication systems on the operational efficiency of financial institutions.
#---
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 2.3775144 0.5244241 4.534 1.71e-05 ***
# X 0.0005766 0.0035582 0.162 0.8716
# monitoring_activities 0.2666477 0.1023902 2.604 0.0107 *
# assign_different_personnel 0.1478683 0.1035997 1.427 0.1568
# replace_redundant -0.0140751 0.0935202 -0.151 0.8807
#---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# Residual standard error: 0.9982 on 94 degrees of freedom
# Multiple R-squared: 0.127, Adjusted R-squared: 0.08986
# F-statistic: 3.419 on 4 and 94 DF, p-value: 0.01177
#---
From the above table we can see:
The variable monitoring_activities (0.0107 *) has influence to the efficiency operation financial institutions.
The variables fulfill the statistical model with p-value: 0.01177 is less than 0.05.
Based on the F-statistic of the model 3.419 and the corresponding p-value: 0.01177. This indicates that the model is statistically significant because the p-value: 0.01177 is less than 0.05













